Finding a definition of artificial intelligence
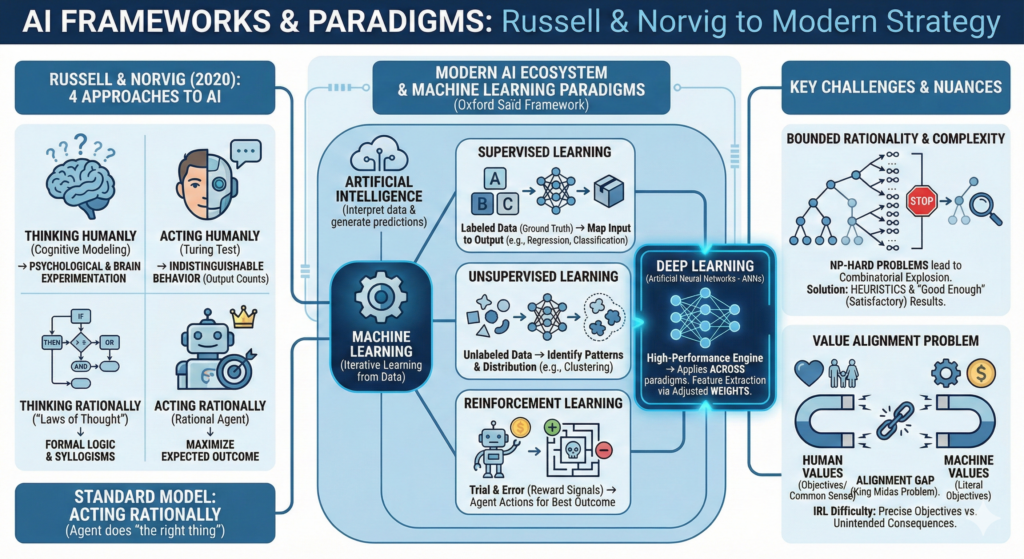
The four approaches to defining AI according to Russell and Norvig (2020):
Acting humanly ( The Turing Test approach)
The output counts. It doesn’t matter how the machine “thinks,” as long as its behavior is indistinguishable from that of a human.
Thinking humanly (The cognitive modeling approach)
The process counts. We must first understand how the human mind works through psychological experimentation or brain imaging, before we can grasp the workings of AI
Thinking rationally (The “laws of thought” approach)
The Logic counts. It relies on formalizing “right thinking” through syllogisms and mathematical logic.
Acting rationally (The rational agent approach)
The best expected outcome counts. A rational agent is something that acts to achieve the best outcome.
Long time now, “acting rationally” was accepted as the standard model.
In our day though, this standard model is problematic because it assumes we can specify objectives perfectly. In the real world, it is very difficult to provide an precise objective to the agent (self driving car, etc…) which leads to the value alignment problem. In theory (and in the lab) the objectives or values of the machine are easily aligned with those of the human, less so IRL. If they are not aligned, we should expect negative consequences, and the more intelligent the system is, the more negative consequences we can expect (Russell, S. and Norvig, P., 2020).
This is why we tend to evolve away from the “Standard Model” and toward a more “Human-Compatible AI”. The Standard Model (“acting rationally”) strives for the optimal result and therefore hits a mathematical wall in the real world because many problems IRL decisions lead to exponentially difficult calculations (i.e. The travelling Salesman problem). These problems are NP-hard (Non-deterministic Polynomial time hard).
In these scenarios, the number of possible combinations grows exponentially as the problem size increases, a phenomenon called “combinatorial explosion”.
Because a computer cannot calculate every possible outcome in a reasonable timeframe, we must accept bounded rationality in these cases. This means the AI uses “cheats”, like heuristics and approximation to find a satisfactory answer rather than a mathematically perfect one, a bit what humans do.
The modern AI framework
Drawing on the framework introduced by Professor Matthias Holweg (Saïd Business School), AI can be viewed as an ecosystem of technologies designed to interpret data and generate predictions without explicit task-specific programming.
Central to this is Machine Learning (ML), which refers to the process in which a machine is trained to learn from a dataset without having been programmed (coded) to do so. It’s iterative, and more data will lead to more adaptation. Machine learning is categorized into three primary paradigms:
Supervised Learning
In the standard workflow, the model uses a training set to map inputs to outputs using labeled examples that act as a cheat sheet. Once trained, the model’s accuracy is verified using a test set, where it attempts to identify new, unlabeled data. The two primary methods for this approach are regression, which predicts continuous numerical values like house prices, and classification, which assigns data to specific categories such as identifying an email as spam or not.
Regression
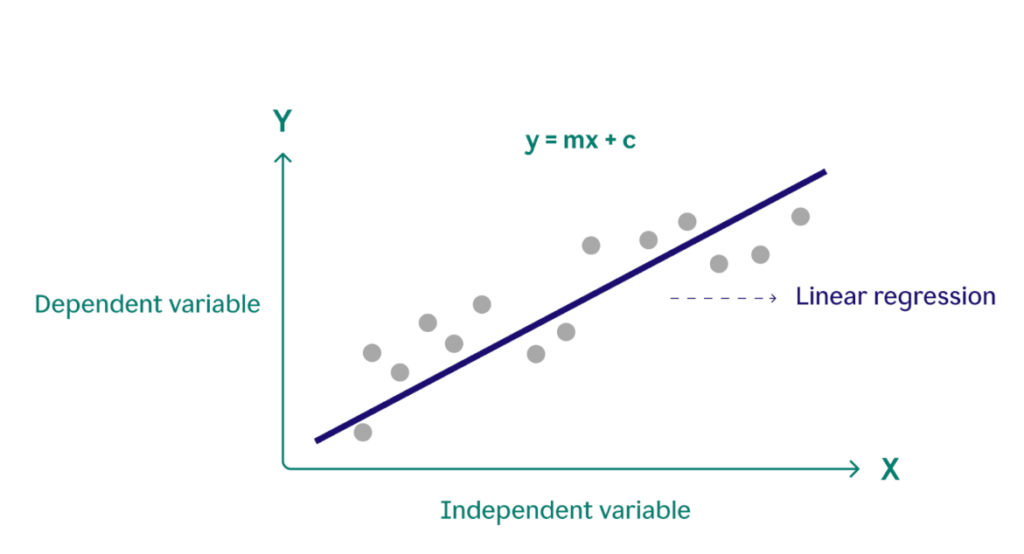
Regression learning is used to predict 1 outcome variable based on a bigger number of input data variables. It’s like finding a continuous trend line through a set of data points and calculate the mean average error from this line. An example of this could be dynamic pricing for a restaurant chain. The restaurant’s AI uses regression to calculate the “extra” amount to charge based on variables like affluence, weather, area code, etc…(You get the bias issue here).
Typically, the output is a number (the most likely outcome) and a certain range around the number (a confidence interval, which is the range that is likely to contain the correct value). There are simple linear regression models, where the relationship between an independent variable (house size) and a dependent variable (house price) is modeled through a straight line:
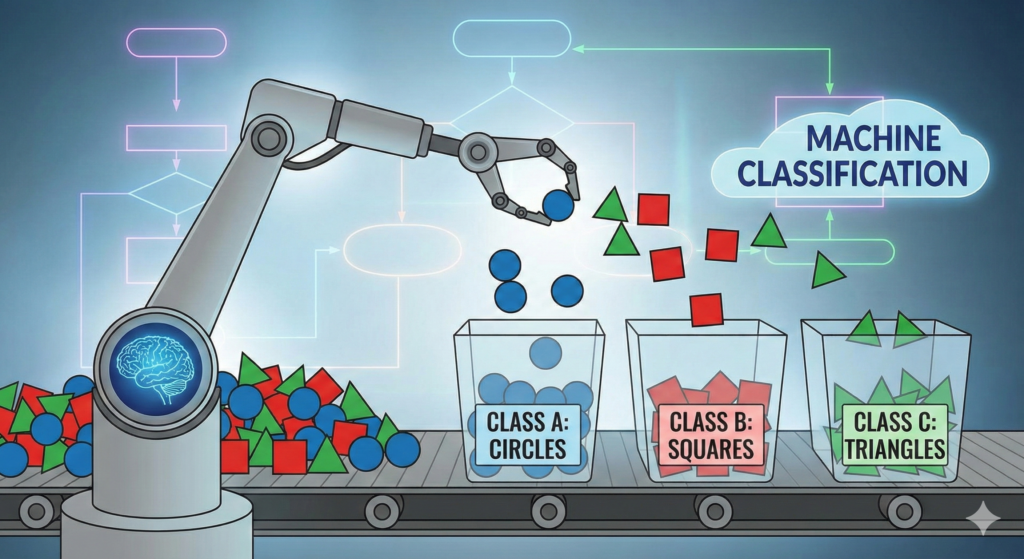
Classification
In classification algorithms, the output variables for classification are categorical. In other words, the classification learning task attempts to map an observation or pattern to a class or category. This is different from regression models where the output is a number.
For a machine to be able to do this, it needs to identify variables, identify the relevant features, and then perform classification.
The main supervised learning algorithms are:
| Linear regression | This algorithm is used for determining a relationship between an independent variable (predictor) and a dependent variable (response) (Swaminathan, 2018a) when the dependent variable is continuous. -> sales forecasting -> Real Estate, Price estimation |
|---|---|
| LASSO and ridge regression | LASSO and ridge regression are closely related extensions of linear regression. They work in a similar way to linear regression, but avoid the problem of “overfitting”, by discounting outliers and extreme values in the analysis. The main difference between these two extensions is that the regularisation in the LASSO method is an absolute value, which has a crucial impact on the trade-off between underfitting and overfitting a model (Chakon, 2017). -> Genomics -> Filtering out noise from sensor networks |
| Logistic regression | This algorithm is used for determining a relationship between an independent variable (predictor) and a dependent variable (response) when the dependent variable is categorical (Swaminathan, 2018b).The output of the logistics regression is a value between 0 and 1. As we will see later, this classification property makes it very useful for creating artificial neural networks. -> Medical diagnostics (Tumor determination) -> Credit scoring |
| Decision trees | Used predominantly for classification, although not exclusively, this algorithm is based on a successive decision process (Bonaccorso, 2017:155). Starting at the “root”, a variable is assessed, and one of two “branches” is selected. This process is repeated until the target variable, in the final “leaf”, is identified (Bonaccorso, 2017:155). -> Customer relationship Management (CRM) software -> Fault/defect identification on production lines |
| Random decision forests | The random decision forest algorithm builds multiple decision trees, which are then combined to create a more accurate model (Donges, 2018). This is referred to as an “ensemble method”, as it combines the outputs of many individual models to reach a decision. -> E-Commerce recommendations -> Classify land cover types in remote sensing |
| Support Vector Machine (SVM) | In this algorithm, each variable is plotted in n-dimensional space, which separates the variables into different classes (Patel, 2017b). Its main application is to classify new data in relation to existing data, for example in fraud detection in financial transaction data, or email spam filters. -> Handwriting recognition -> Protein fold recognition |
Unsupervised Learning
Unsupervised learning is when a machine finds patterns in data without any “explicit feedback”. Unlike other methods where we tell the AI the “right answer” during training, this approach only looks at the input variables. There are no pre-defined labels or “output variables” to guide it. The goal is for the machine to figure out the underlying structure of the data on its own. It looks at the mess of information and decides how to classify or group/cluster it.
To do this, the algorithm uses math to measure the “distance” between data points. Points that are mathematically “close” to each other are grouped together, while points that are far apart are separated. Common algorithms for this include:
| k-means | Using unstructured data, the k-means algorithm clusters data according to features of similarity, with k denoting the number of clusters (Trevino, 2016). The value k is a “hyperparameter”, that is, chosen by the data scientist before the model runs. -> market segmentation for ad targeting -> image compression (grouping of similar pixels) |
|---|---|
| Naïve Bayesian Classifier | Bayes’ Theorem can be used in machine learning too, and it works well for both clustering and classification. When used in clustering, any new datapoint updates the “prior”, and thus builds the clusters from the ground up. Its main advantage is that it works well where there is only little data available to make predictions. -> Sentiment Analysis -> Real-time weather filtering to adapt forecast |
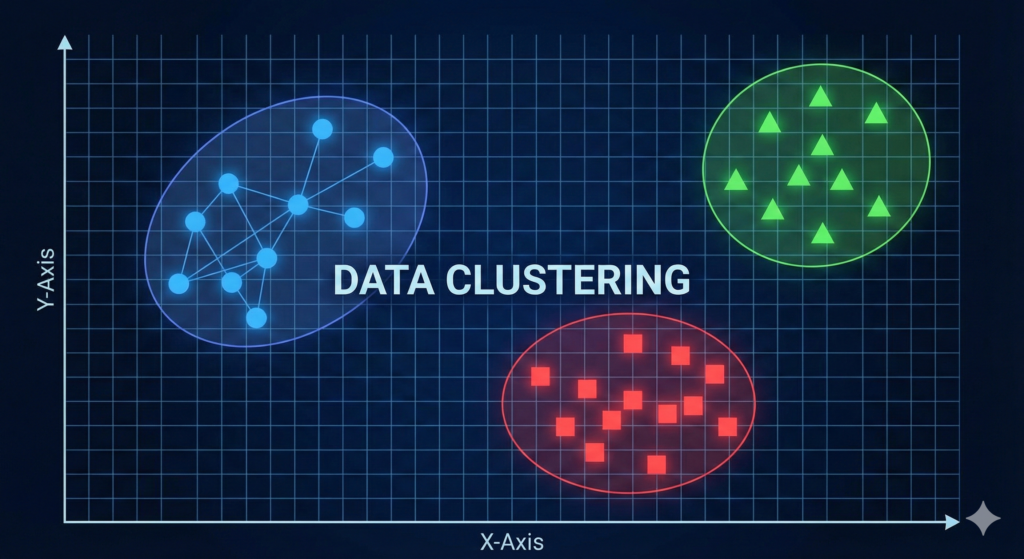
Clustering
In Clustering we are not looking for a data output, but we are looking for association (similarities) between data points. It aims to organize data by identifying shared characteristics. Unlike other methods where you give the machine the answer key, clustering allows the system to find the “hidden” structure on its own.
For this, the machine analyzes input variables and bundles them into groups based on their traits.
Reinforcement Learning
In reinforcement learning a machine learns by examining the outcomes that follow each behavior. It takes a learning-by-doing approach to machine learning, where machines learn through trial and error based on reward signals given for correct solutions.
If the feedback is negative, the algorithm is unlikely to perform that action again, and if the feedback is positive, it is more likely to produce that specific output. No Training Data is needed because the training data is generated by the algorithm itself as it tries, fails and succeeds. This is the realm of AI agents.
The downside of reinforcement learning is that the algorithm needs to operate within an environment where it can fail. So, for example, it’s good for applications like gaming or drug discovery. (AlphaGo and AlphaFold). However, reinforcement is a poor approach in the realm of autonomous vehicles, as allowing for failures could result in potentially dangerous crashes.
Reinforcement learning is the negotiation between exploration and exploitation. To maximize rewards, a machine must exploit known successful behaviors while simultaneously exploring new ones to discover better outcomes. This trial-and-error balance makes it the machine learning approach most similar to how humans learn.
Reinforcement learning offers great promise in various settings, especially if the following three conditions are true:
- The context or environment is complex;
- Training data is not available; and
- Continuous learning is possible (and safe).
Reinforcement learning (RL) excels by generating its own training data through real-time experience. By treating every success or failure as a data point, the algorithm “learns by doing,” much like a human.
The strengths of reinforcement learning are:
- Self-Sustaining: Data is created dynamically during the process, removing the need for pre-labeled datasets.
- Emergent Innovation: Without rigid instructions, algorithms often develop creative, “out-of-the-box” strategies to solve problems.
- Complexity Handling: Ideal for chaotic environments and tasks requiring continuous adaptation.
Limitations:
Rigidity in Reality: It struggles in nuanced settings where success is defined by multiple, conflicting variables or vague objectives.
Reward Dependency: Requires a precise, singular reward function to define success.
The most used RL algorithms are:
| Q-learning | A reinforcement learning method where the values of actions in states are stored in a Q-table to calculate the expected future rewards for each action in each of the possible states (ADL, 2018). The algorithm performs, in effect, a true “trial and error” strategy, and changes its behaviour in relation to past experience. -> Automated warehouse routing ->Traffic light control system |
|---|---|
| Policy gradient | Policy gradient algorithms work just like Q learning, but here a hyperparameter is chosen by the data scientist that sets the balance between “exploring” new solutions, versus “exploiting” solutions that were found to work in past rounds. -> Robotic limb control -> Algorithmic trading |
Then, there is Deep Learning.
Deep learning is an architectural approach using artificial neural networks (ANN), that can be used inside the previous mentioned paradigms, a bit like a high performance engine, like so:
- Supervised Deep Learning (Image recognition)
- Unsupervised Deep Learning (like GenAi and LLMs)
- Deep Reinforcement Learning (AlphaGo)).
(For business strategy, it might be useful to explain and situate Deep Learning as separate from the normal definitions of ML because the mechanics are so fundamentally different.)
In Deep learning, algorithms process input variables according to PARAMETERS, which are typically weights of the connections. These weights are adjusted at each iteration, so that the neural network learns to produce the correct result.
Learning occurs through ADJUSTING these weights in order to improve and predict output.
Here are the most used algorithms of deep learning:
| Convolutional neural networks (CNN) | Convolutional neural networks are the classic method used for image recognition. The algorithm uses different types of layers that extract and pool features from input images to differentiate different objects in the image (Saha, 2018). -> Medical imaging (identifying anomalies) -> Facial recognition systems |
|---|---|
| Recurrent neural networks (RNN) | A form of neural network that includes loops or connections between the different layers in the network, and neurons in the same layer. “A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor” (Banerjee, 2018). The most efficient RNN is called LSTM, which stands for “Long Short-Term Memory”, and is an RNN that in effect has a memory function that can store the last value. This is very helpful when working on sequential data like language or speech. -> Speech to Text transcription -> Finance market predictions |
| Encoders and transformers | The most recent developments of neural networks in natural language processing are so-called encoder-decoder models, and transformer models. They combine several neural networks within an architecture that allows for the inputs and outputs to have different formats. This is very helpful when analysing or generating language but can also be used for image processing. ChatGPT, Claude, and Gemini are very powerful examples of modern transformer models for language generation and analysis, which combined are often referred as “LLMs – large language models”. -> Real time language translations -> Automated document summarisation -> Automated Coding Assistance -> Live customer support |
References:
- Russell, S. and Norvig, P. (2020) Artificial Intelligence: A Modern Approach. 4th edn. Hoboken: Pearson.
- Holweg, M. (2026) Artificial Intelligence: A Framework for Business. [Course Material] Saïd Business School, University of Oxford (https://www.sbs.ox.ac.uk/programmes/executive-education/online-learning/oxford-artificial-intelligence-programme)
- Google Gemini 3 for some precision enhancements